Architecture
A local gateway, invisible to your workflow
Kiri runs on localhost and intercepts every outgoing LLM call. No changes to your tools. No cloud component. No data leaving your machine.
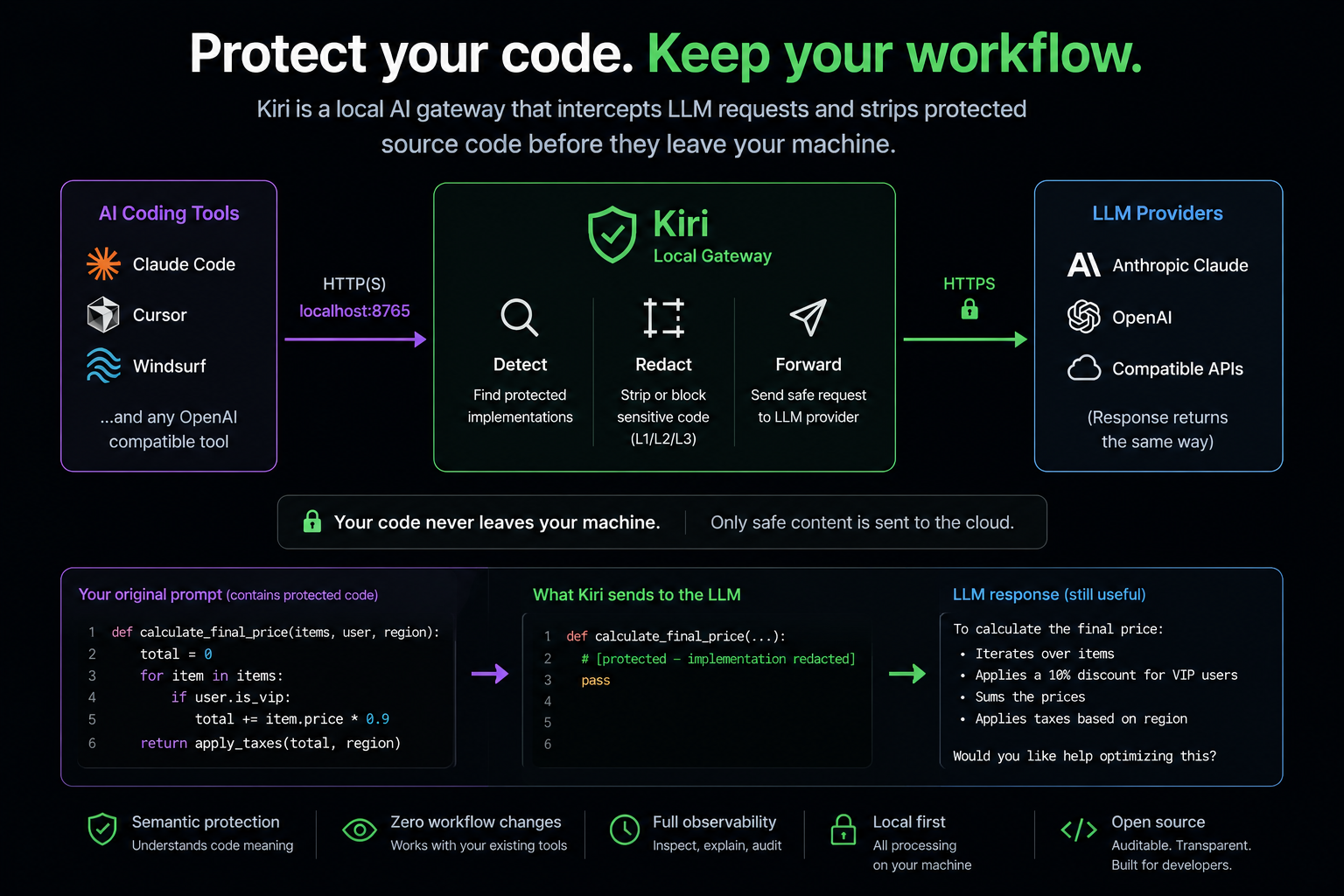
All processing runs inside Docker on localhost. The real API key lives only inside the container as a Docker secret. · Filter pipeline spec →
